A new AI research paper titled EarlyTom proposes early-stage token compression for Video-LLMs, reducing computation costs while significantly improving inference speed.
Imphal, May 31: A newly released AI research paper titled “EarlyTom: Early Token Compression Completes Fast Video Understanding” is drawing attention within the machine learning community for proposing a practical way to significantly speed up video-based large language models without retraining them.
The paper focuses on one of the growing technical challenges in artificial intelligence: the massive computational cost of processing video data in multimodal systems.
As AI models increasingly move beyond text and images into full video understanding, developers are facing an escalating problem. Every second of video generates thousands of visual tokens that must be processed by large vision encoders before the language model can reason about the content. This creates high latency, increased GPU usage and rising deployment costs.
The researchers behind EarlyTom argue that most existing optimization techniques address the problem too late in the inference pipeline.
The Bottleneck Inside Video-LLMs
Modern Video Large Language Models, commonly called Video-LLMs, combine visual encoders with language reasoning systems. These models are designed to interpret and respond to video content in a conversational or analytical manner.
Applications include:
- AI video assistants
- Autonomous robotics
- Smart surveillance systems
- Educational video analysis
- Real-time sports or traffic monitoring
- Long-context video summarization
However, the computational burden grows rapidly as video duration increases.
Unlike static image systems, video models must process temporal information across multiple frames. A short clip may already generate tens of thousands of visual tokens. Much of the computational load falls on the vision encoder, which converts raw visual input into representations usable by the language model.
According to the paper, many existing token-compression methods only reduce tokens after the vision encoder has already completed most of its expensive calculations. By that point, substantial computational resources have already been consumed.
EarlyTom attempts to address this inefficiency earlier in the process.
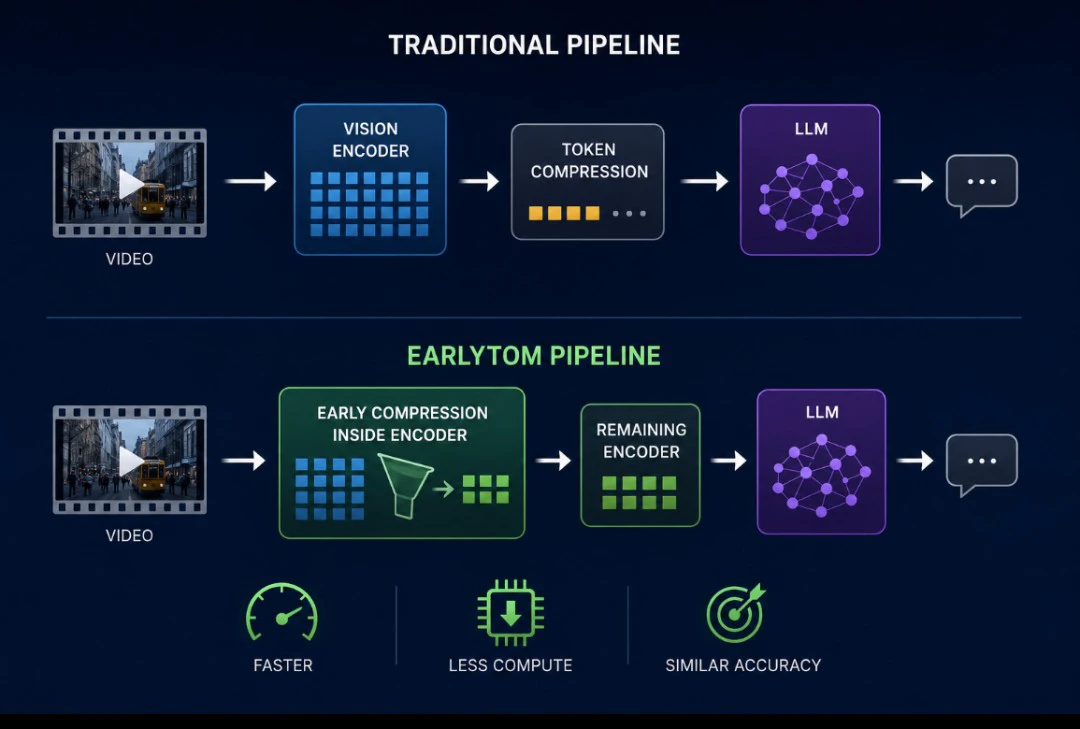
Compressing Tokens Earlier in the Pipeline
The central idea behind EarlyTom is relatively straightforward but technically significant.
Instead of compressing visual tokens after feature extraction, the framework performs token reduction within the vision encoder itself. This means later stages of the encoder process fewer tokens, reducing computational overhead throughout the remaining pipeline.
The approach is described as “early token compression".
In practical terms, the workflow changes from:
Video → Full Vision Encoding → Token Compression → Language Reasoning
to:
Video → Early Compression During Encoding → Reduced Processing → Language Reasoning
The distinction may appear subtle, but it affects where computational savings occur.
By eliminating redundant visual tokens earlier, the system avoids unnecessary processing during later encoder stages. The paper claims this substantially reduces latency and floating point operations without severely affecting accuracy.
Training-Free Design Could Increase Adoption
One aspect receiving particular attention is that EarlyTom is described as a training-free method.
The framework reportedly does not require:
- retraining,
- additional fine-tuning,
- new datasets,
- or architectural redesigns.
This is important because retraining large multimodal models is extremely resource-intensive. Training advanced video-language systems can require enormous GPU clusters, extended compute time and significant financial investment.
A training-free optimization method is therefore more attractive for deployment-focused companies and research groups already operating large pretrained models.
The paper demonstrates the approach on LLaVA-OneVision-7B, a multimodal AI model used for visual understanding tasks.
According to the reported benchmarks, EarlyTom achieved:
- up to 2.65 times faster Time-to-First-Token,
- around 61 percent reduction in FLOPs,
- while maintaining performance close to baseline accuracy levels.
Although independent benchmarking is still limited, the reported improvements are substantial enough to attract interest from developers working on scalable video AI systems.
A Broader Shift Toward Efficient AI
The release of EarlyTom also reflects a wider trend emerging across the AI industry in 2025 and 2026.
For several years, the dominant strategy in AI development focused heavily on scaling — larger datasets, larger models and more parameters. But as deployment costs rise, researchers are increasingly focusing on efficiency rather than raw scale alone.
This includes work on:
- sparse attention systems,
- dynamic computation,
- token pruning,
- mixture-of-experts routing,
- KV-cache optimization,
- and adaptive inference architectures.
EarlyTom fits within this broader efficiency-oriented movement.
Instead of increasing model size, the paper focuses on reducing unnecessary computation during inference. That direction is becoming increasingly relevant as AI companies attempt to deploy multimodal systems in real-world environments where latency, memory usage and energy consumption matter.
The challenge is especially important for edge computing devices, robotics and mobile AI systems where hardware resources remain constrained.
Implications for Real-Time Video AI
If techniques like EarlyTom prove robust across additional architectures, they could influence the next generation of real-time AI systems.
Video understanding remains one of the most computationally demanding areas in artificial intelligence. Real-time responsiveness is difficult because models must simultaneously process spatial and temporal information across large frame sequences.
Reducing latency while preserving reasoning quality is therefore a major engineering goal.
Potential use cases include:
- live AI assistants,
- autonomous navigation systems,
- industrial monitoring,
- smart city infrastructure,
- defence surveillance systems,
- and advanced human-computer interaction platforms.
In many of these environments, response speed is not simply a convenience feature but an operational requirement.
The paper also raises broader questions about whether future AI breakthroughs may increasingly come from architectural efficiency rather than only expanding model scale.
That debate is becoming more prominent as the industry confronts rising infrastructure costs and growing energy demands associated with frontier AI systems.
Questions Still Remain
Despite the promising benchmarks, several questions remain open.
The paper’s reported results are currently tied to a specific architecture and hardware setup. Broader validation across different Video-LLMs and deployment environments will likely determine how widely the technique can be adopted.
Researchers will also examine:
- whether compression affects reasoning reliability in long videos,
- how the system performs on highly dynamic scenes,
- and whether token reduction introduces subtle information loss in safety-critical applications.
As with many AI efficiency techniques, performance trade-offs may vary depending on workload type and deployment context.
Still, the core insight behind EarlyTom — reducing unnecessary computation earlier in the visual pipeline — is already being viewed as a meaningful contribution to ongoing work in scalable multimodal AI.
With video expected to become one of the next major frontiers for artificial intelligence systems, methods that lower computational barriers may play a central role in shaping how future AI infrastructure is designed.





